Layered Query Language (LQL) is a language developed by Preslav Nakov, Ariel Schwartz, Brian Wolf and Marti Hearst of the Berkeley BioText project. Its goal is to be an intuitive, simple way to query for ranges of text from a database of documents. The text of these documents must first be annotated using any natural language processing method. The processing done by the BioText group creates several annotation layers that allow powerful querying of the text.
Examples of domain-independent layers that can be built on any collection of documents are: the sentence
layer, the full_parse layer, the shallow_parse layer, the part-of-speech (pos) layer,
and the word layer. The current annotation method does not include the word layer, as it is
indistinguishable from the pos layer. The Biotext group has developed several layers for use in annotating
biology texts, including the gene/protein layer, the MeSH layer (labeled the ontology layer in the
following diagram), and the chemical layer. See diagram below.
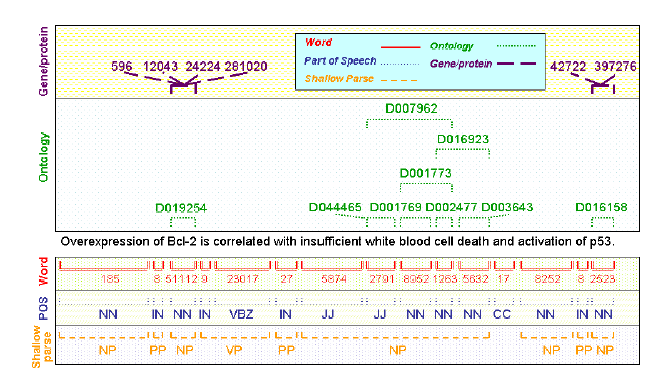
An annotation can be thought of as a range of text that also comes with certain properties. Every annotation has the
following properties: layer (the annotation layer into which the annotation was categorized by the natural
language processor), start_char_pos (the index of the first character), end_char_pos (the index
after the last character), tag_type, and text (the text from the original document that occurs
between start_char_pos and end_char_pos). Also, as the BioText group annotates PubMed documents,
every annotation has the property pmid.
So, for example, if you wanted a table of all of the sentences in all of the documents in the database, your query would look like this:
FROM [layer='sentence'] AS sen SELECT sen.text
In the above example, the expression [layer='sentence'] matches all ranges of text whose start and end
positions coincide with the start_char_pos and end_char_pos attributes of some
sentence annotation. The AS sen binds the variable sen to each of these ranges, and the
statement SELECT sen.text says to return a table containing the content of all of the ranges of text bound to
sen.
The bit of code layer='sentence' is a test on the annotation, which must evaluate to true in order for the
query to match. More complex tests are possible.
FROM [layer='sentence' && text ~ '%Berkeley%'] AS sen SELECT sen.text
In LQL, the operator ~ is bound to the LIKE operator
in SQL. Thus, the character '%' matches any sequence of characters of any
length, and the character '_' matches any single character. The above query, therefore, would return a table of all sentences
containing the string "Berkeley".
The above query would be one way to retrieve all sentences containing the word "Berkeley." However, the current
implementation of the annotation database only stores the text of whole documents, rather than the text of each annotation.
Thus, though the text property is available in the SELECT clause (after the annotations have been
matched and processed), it cannot be part of the test on a layer. Fortunately, LQL allows ranges to be nested. Thus, to
obtain a table of all sentences containing the word "Berkeley", write the following query:
FROM [layer='sentence'
[layer='pos' && content='Berkeley']
] AS berk_sen
SELECT berk_sen.text
This query uses the content property that is unique to the pos layer. The assertion of this
query is that there is a word annotation whose content is "Berkeley" (with exactly that case) contained within
the range of a sentence annotation. The text of the sentence is returned.
The pos layer also has a content_lower property. A note about string comparisons:
case-sensitivity of the tests is dependent on the underlying database implementation. Our implementation has content compare
in a case-sensitive manner. We have created the content_lower property, which is the result of converting all of
the letters in the content property to lower case, to allow testing while ignoring case.
Using double quotes ["] around a string causes the test not to compare the string to the property that the user
specified, but to a property it acts as an alias for. For example, content is an alias for
content_lower. Thus, typing the test content="berkeley" has exactly the same results as typing the
test content_lower='berkeley'. In other words, both of these tests will also match a word whose
content property is "Berkeley", "berkeley", "BERKELEY", or "bErKeLeY", as every word with any of these as its
content property will have "berkeley" as its content_lower property.
Any range may contain multiple internal-ranges.
FROM [layer='sentence'
[layer='pos' && content="attends"] AS attends
[layer='pos' && content='Berkeley']
] AS attendance
SELECT attendance.text, attends.content
(Note that the double quotes around "attends" cause the test for that annotation to be interpreted as layer='pos' &&
content_lower='attends'. Thus, the value returned by attends.content in the SELECT clause
may contain some capitalized letters.)
The preceding query selects all sentences which contain the word "attends" immediately followed by the word "Berkeley". This is the default behavior when multiple ranges are asserted to occur within the same enclosing range: they must be adjacent and in the order specified. The behavior can be modified.
FROM [layer='sentence' { ALLOW GAPS }
[layer='pos' && content="attends"]
[layer='pos' && content='Berkeley']
] AS attendance
SELECT attendance.text
The above query specifies that the ranges contained within the sentence annotation need not be sequential in order for the query to match. Thus, the above query will match any sentence that contains the word "Berkeley" somewhere after the occurrence of the word "attends." To find all sentences containing both words but in either order, use the following query:
FROM [layer='sentence' { NO ORDER, ALLOW GAPS }
[layer='pos' && content="attends"]
[layer='pos' && content='Berkeley']
] AS attendance
SELECT attendance.text
Say you want to find all sentences containing the word "attends" and the phrase "UC Berkeley."
FROM [layer='sentence' { NO ORDER, ALLOW GAPS }
[layer='pos' && content="attends"]
[layer='pos' && content='UC']
[layer='pos' && content='Berkeley']
] AS attendance
SELECT attendance.text
This query may return unintended results, because it does not require the word "UC" to immediately precede the word "Berkeley." The way to solve this problem is to introduce a new range which will default back to enforcing a sequential order.
FROM [layer='sentence' { NO ORDER, ALLOW GAPS }
[layer='pos' && content="attends"]
[layer='shallow_parse' && tag_name='NP'
[layer='pos' && content='UC']
[layer='pos' && content='Berkeley']
]
] AS attendance
SELECT attendance.text
Here, the range matching the shallow_parse reverts to the default behavior { ORDER, NO GAPS },
so this query does require the words "UC" and "Berkeley" to be adjacent. However, this is a very verbose way to get around
the adjacency problem, and it also requires the sentence to be parsed such that the words "UC" and "Berkeley" appear in the
same noun phrase shallow parse annotation. (tag_name is a property of the shallow_parse and
pos layers.)
FROM [layer='sentence' { NO ORDER, ALLOW GAPS }
[layer='pos' && content="attends"]
( [layer='pos' && content='UC']
[layer='pos' && content='Berkeley']
)
] AS attendance
SELECT attendance.text
The parentheses in the above query create an artificial range. This range acts like an annotation range in that it can
contain nested ranges, and it acts as though it has the start_char_pos and end_char_pos properties
for the purposes of testing the order and sequentiality of other ranges nested in its parent range. However, it should not be
given a name (with the AS operator), and its properties cannot be tested or returned in the SELECT
clause. The artificial range has the default behavior { ORDER, NO GAPS }.
FROM [layer='sentence' { NO ORDER, ALLOW GAPS }
[layer='pos' && content="attends"]
[layer='shallow_parse' && tag_name='NP'
[layer='pos' && content='UC']
] AS school
] AS sentence
SELECT school.text, sentence.text
The above query is designed to find all sentences stating that someone attends some UC, and return the name of that campus (assumed to be the noun phrase containing the word "UC") as well as the sentence matched.
Just to show a little more of the power of the language:
FROM [layer='sentence' { NO ORDER, ALLOW GAPS }
[layer='pos' && content="attends"]
[layer='shallow_parse' && tag_name='NP'
[layer='pos' && content='UC']
[layer='pos' && ( content='Berkeley'
|| content='Davis'
|| content='Irvine'
|| content='Los' -- it is expected that this will be followed by 'Angeles'
|| content='Merced'
|| content='Riverside'
|| content='San' -- it is expected that this will be followed by either 'Diego' or 'Francisco'
|| content='Santa' -- it is expected that this will be followed by either 'Barbara' or 'Cruz'
)
] AS city
] AS campus
] AS sentence
SELECT city.content, campus.text, sentence.text
Note the comments in the above query that use the same comment syntax as SQL — two hyphens '--' begin a comment that lasts until the end of the line.
The special characters ^ and $ can be used as in regular expressions when specifying internal ranges.
FROM [layer='sentence'
[layer='pos' && content="university"] $
] AS s
SELECT s.text
This query will return all sentences ending with the word "university."
FROM [layer='sentence'
^ [layer='pos' && content="class"]
] AS sen
SELECT sen.text
This query will return all sentences beginning with the word "class."
As described above, it is possible to create domain-dependent layers. One such layer is the MeSH layer. For
example:
FROM [layer='shallow_parse' && tag_name="NP"
[layer='pos' && tag_name="noun"
[layer='mesh' && tree_number BELOW 'A01']
] AS m1
[layer='pos' && tag_name="noun"
[layer='mesh' && tree_number BELOW 'A07']
] AS m2 $
]
SELECT m1.content, m2.content
This query looks for two adjacent nouns in the same noun phrase, the first of which falls within the A01 sub-hierarchy of the MeSH hierarchy, which happens to be Body Regions, and the second of which has been categorized in the A07 sub-hierarchy, which is Cardiovascular System. The second noun must be the last word in the noun phrase, as indicated by the '$' in the query.
Something else to note here: the query asserts that the MeSH term should occur within a noun pos
annotation. Since the purpose of this nesting is simply to assure that the MeSH term matched is a single noun, the query
could have written as [layer='MeSH' && tree_number BELOW 'A01' ^ [layer='pos' && tag_name="noun"] $]. The point
here is that the annotations overlap, and the annotation ranges in the query are both intended to match the same word, so it
doesn't matter in which order they are specified in the query.
Regarding overlap, there are plans possibly to handle overlapping ranges of text. This functionality hasn't been completely developed, but it may be possible to rewrite the above query as something that resembles the following:
FROM [layer='shallow_parse' && tag_name="NP"
( { FULL_OVERLAP }
[layer='pos' && tag_name="noun"] AS m1
[layer='MeSH' && tree_number below 'A01'] )
( { FULL_OVERLAP }
[layer='pos' && tag_name="noun"] AS m2
[layer='MeSH' && tree_number below 'A07'] )
$
]
SELECT m1.content, m2.content
The idea here is that it is specified that the two sub-ranges of each artificial range must completely overlap, i.e., that they must cover the same range of text.
Last updated: 2005-06-28 17:06